VOLE: The engine behind modern MPC and ZK
From Oblivious Transfer to arithmetic correlations for secure computation
to help others discover it! 🥰
Thanks a lot to Geoffroy Couteau who helped me a lot in understanding some of these constructions

OLE#
Oblivious Linear Evaluation (OLE) is a cryptographic protocol in which two parties interact to compute an affine function without revealing their private inputs. Specifically:
- the sender holds two values: , where is a finite field
- the receiver holds a value
At the end of the protocol, the receiver learns the result of the affine function evaluated at
However, the receiver learns nothing about and beyond the result, and the sender learns nothing at all, not even the receiver's input .
Another way to describe this is private affine function evaluation: the receiver learns the output of a function defined by the sender, without learning the function itself.
OLE can be seen as a generalization of Oblivious Transfer (OT) over larger fields.
In the special case where , OLE behaves like a 1-out-of-2 OT. The sender chooses two values:
Which gives the OLE equation:
Then the receiver, holding a selector bit , receives:
This can be interpreted as choosing between the two values and , depending on , just like OT.
OLE has a variety of applications in secure computation, including:
- Commitment to a value (the witness)
- Secure arithmetic: enabling two parties to jointly compute multiplications or additions on hidden inputs.
Let’s now explore these two use cases in more detail.
OLE as a Commitment Scheme#
An Oblivious Linear Evaluation can be used for the sender (often called the prover) to commit to a hidden value , typically a witness. This commitment has two key properties:
- Hiding: The receiver (or verifier) learns nothing about
- Binding: Once the commitment is made, the prover cannot change the value of without being caught.
How does this work?
After performing the OLE protocol, the verifier receives a value such that:
Here, is a secret value known only to the verifier, and is a random value held by the prover. You can think of as a MAC (Message Authentication Code): it masks the value while still binding it to the commitment.
Because is hidden from the prover, the probability that they can find another pair such that:
is extremely small, unless they know .
If either or is revealed, the security of the commitment collapses. But as long as they remain secret, the commitment is both hiding and binding.
This simple mechanism becomes even more powerful when we consider the homomorphic properties of OLE commitments: we can combine them without ever revealing the underlying values.
Note: In practice, protocols rarely involve just a single OLE. Instead, many OLEs are executed in parallel, all using the same fixed value , chosen by the verifier at the start of the protocol.
Homomorphic Combination#
Suppose the prover has committed to two values and using OLE, resulting in:
The verifier can add their commitments:
And the prover can do the same with their values:
Then, the combined commitment still holds:
or:
This additive homomorphism allows commitments to be aggregated or manipulated algebraically without revealing any private inputs.
Magic? Almost 🦄
OLE for Computation on Hidden Values#
One really powerful use case of Oblivious Linear Evaluation is enabling arithmetic over hidden inputs. In other words, two parties can compute basic operations like multiplication or addition without revealing their private values to each other.
That said, it’s a bit more subtle than “just compute a + b or a × b”.
In fact, with the help of OLE, you can transform addition into multiplication, or vice versa, and that opens up a lot of possibilities.
Let’s walk through how it works, and why that’s useful.
🔄 M2A / A2M
In Multiplication-to-Addition (M2A), we want to convert the product of two secret values into additive shares: two values that sum to the result, each held privately by a different party.
Let’s say:
- the sender (Prover) holds a secret value
- the receiver (Verifier) holds a secret value
They want to compute:
where and are secret shares, one held by the sender and the other by the receiver.
To do this, they perform an OLE:
- the sender inputs (the multiplier) and a random mask
- the receiver inputs as the evaluation point
As a result, the receiver learns:
Now both parties hold additive shares of :
- the sender keeps
- the receiver has
So together:
Magic: the product is now split into two hidden pieces. No one ever saw both inputs, and yet the result is correct.
How does it work?
You can find a working example in m2a.py over at https://github.com/teddav/mpc-by-hand.
Let’s start simple. Suppose you want to compute (no hidden value here). You already know the binary representation of b.
You can just do:
import random
p = 257
def to_bin(v):
return [int(i) for i in list(bin(v)[2:])]
a = random.randint(0, p)
b = random.randint(0, p)
print("a =", a, ", b =", b)
print("a * b =", (a * b))
b_bits = to_bin(b)[::-1]
t = [(a * pow(2, i)) for i in range(len(b_bits))]
tb = [t[i] if bit == 1 else 0 for i,bit in enumerate(b_bits)]
print("tb =", sum(tb))
assert sum(tb) == (a * b)
What's going on here?
b_bits is the binary representation of b (in little endian).
→ so… is just based on the binary representation of b
Let’s detail:
or:
Say , so in binary:
That’s:
Then:
So we just sum a, shifted accordingly based on which bits of b are 1.
Now we understand how to multiply two numbers using the binary representation of the second.
In M2A, we do pretty much the same thing, but the sender hides their value using a random mask. Then, using oblivious transfer, the receiver learns the masked version of the relevant terms, only for the bits where .
So the multiplication happens, but the inputs stay hidden.
You can follow the script for a full walkthrough. It’s commented and walks you through this logic step by step.
A2M: opposite direction
Addition-to-Multiplication (A2M) is the inverse of M2A: starting from two additive shares of a value, you convert them into multiplicative shares. This is useful when a protocol needs multiplicative structure.
Example 1: MPC-TLS
M2A and A2M aren’t just academic tricks, they’re used in real-world privacy tools like MPC-TLS, the core protocol behind TLS Notary.
The goal of MPC-TLS is to allow users to securely prove the content of an HTTPS session, without revealing sensitive data.
Let’s recap how a regular TLS handshake works: when your browser connects to a website, it performs a key exchange with the server to agree on a shared encryption key. That key is then used to encrypt all future traffic.
In MPC-TLS, there’s a third party: the Notary, acting as a proxy. The browser and the notary each hold a secret share of the TLS session key, and use MPC techniques to cooperatively compute the handshake and decryption, without ever revealing their shares to each other.
M2A and A2M are core primitives here. They allow the browser and notary to securely perform multiplications and additions over secret values as part of the handshake.
If you're curious about how the full protocol works, check out Section 4.3.1 of this paper. Once you're familiar with OLE, M2A, and A2M, the rest falls into place.
Example 2: Private Information Retrieval
Another great real-world use case for OLE is Private Information Retrieval (PIR).
In a PIR protocol, a user queries a database and gets back the result they wanted without revealing which item they asked for 🤯 The database does all the work but stays completely in the dark about what was accessed.
OLE can be used to build efficient PIR schemes where the database holds a vector, and the user interacts with it using arithmetic encodings of their query, without leaking the index.
If you're curious about how this works under the hood, check out this paper.
VOLE#
A Vector Oblivious Linear Evaluation (VOLE) is an extension of OLE to vectors. Instead of evaluating a single affine function, the protocol generates many OLE-like relations in parallel, efficiently and securely.
Like OT and OLE, VOLE involves two parties. After running the VOLE protocol, each party holds the following:
- Sender (or prover)
- : a secret vector of values (the committed data)
- : a random mask (used as a MAC to hide )
- Receiver (or verifier)
- : a fixed, secret scalar
- : a vector of OLE outputs
These values satisfy the following relation:
That is, for each index , the pair satisfies:
You can think of this as running independent OLEs: one for each index, all using the same secret .
But instead of performing them individually, we want a much more efficient way to generate large VOLEs. That’s what we’ll explore next.
Silent VOLE#
How can we efficiently generate a large number of VOLE correlations while using very little communication and minimal computation?
The answer lies in combining two powerful tools: the GGM tree and the Learning Parity with Noise (LPN) assumption.
GGM tree#
The Goldreich–Goldwasser–Micali (GGM) tree is a method for generating a large amount of pseudorandom data from a small secret seed. It was originally introduced as a way to construct pseudorandom functions (PRFs) from a pseudorandom generator (PRG).
It's widely used in secure multiparty computation (MPC), game theory, and distributed protocols where multiple parties need to generate randomness fairly and securely, without relying on a trusted third party.
At its core, the GGM construction organizes the output of a PRG into a binary tree structure:
- you start with a seed at the root
- At each level, the PRG is used to derive two child seeds from each parent seed, typically one for the left child and one for the right
- Repeating this process builds a binary tree of depth , which gives you pseudorandom values from a single seed
graph TD
S[root seed]
S --> A0[Node A0]
S --> A1[Node A1]
A0 --> B00[Node B00]
A0 --> B01[Node B01]
A1 --> B10[Node B10]
A1 --> B11[Node B11]
B00 --> C000[Node C000]
B00 --> C001[Node C001]
B01 --> C010[Node C010]
B01 --> C011[Node C011]
B10 --> C100[Node C100]
B10 --> C101[Node C101]
B11 --> C110[Node C110]
B11 --> C111[Node C111]
This process is deterministic: the same seed always generates the same tree. But to anyone without the seed, the outputs are computationally indistinguishable from random.
One of the most powerful features of the GGM tree is its local revealability: if you share the seed of any internal node (= a subtree root), you reveal all pseudorandom values in that subtree, and nothing outside of it.
This makes it ideal for selective access control, such as in verifiable secret sharing, oblivious transfer extensions, or randomness beacons in MPC.
This property makes the GGM tree especially useful in protocols where parties should only access specific parts of the pseudorandom data without learning the rest. We’ll see exactly how this plays a role in VOLE and Quicksilver shortly.
LPN#
The Learning Parity with Noise (LPN) problem is a foundational assumption in modern cryptography, and importantly, it's believed to be secure even against quantum adversaries.
You can think of LPN as the binary (mod 2) analogue of the more widely known Learning With Errors (LWE) problem. Despite its simplicity, it's powerful enough to build a wide variety of cryptographic primitives.
We'll use what’s known as the dual form of LPN in our protocol, but let’s first understand the primal form, which is easier to visualize.
Primal form
In the primal form, we generate noisy linear combinations of a secret vector:
- , a public matrix (over )
- , the secret vector we’re committing to
- , a sparse noise vector
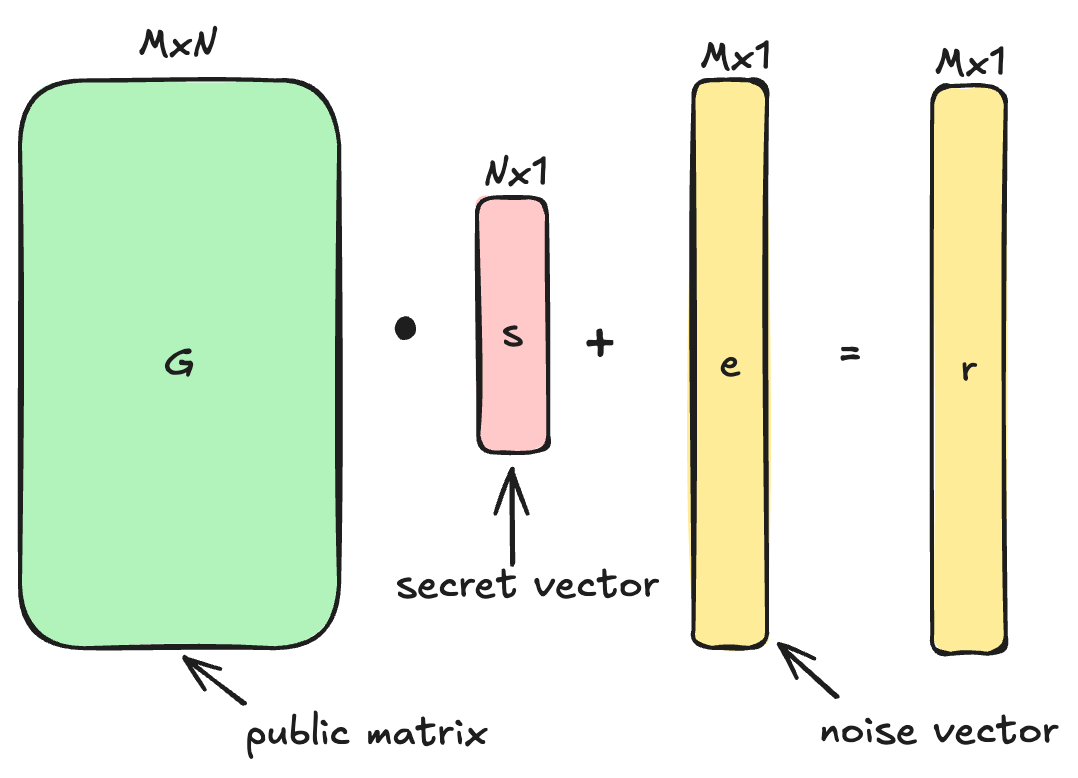
Then we get:
Given only and , recovering is surprisingly hard, thanks to the small amount of noise . That's what makes LPN powerful as a cryptographic building block.
Here’s a visual example with integers, coming from Jun’s blog, which gives a great explainer on the topic.
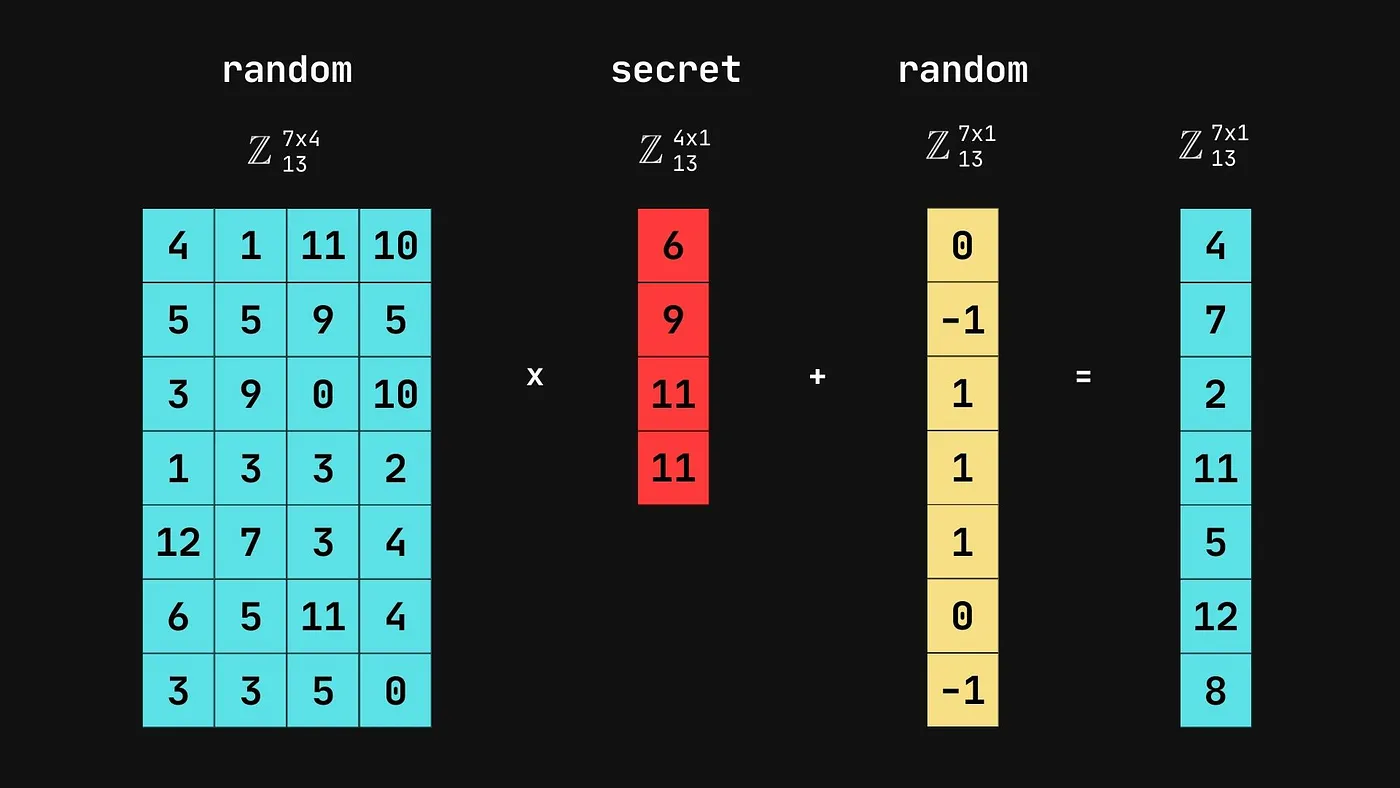
Even in small dimensions, the presence of a few random bit flips makes the problem hard to solve.
Dual form
The dual form is a clever transformation of this problem.
Instead of trying to find a secret , we try to eliminate it entirely to isolate the noise , which now becomes the secret we want to protect.
Starting from the primal equation:
We multiply both sides by a carefully chosen matrix , such that “cancels out” . In other words, lies in the left null space of , or :
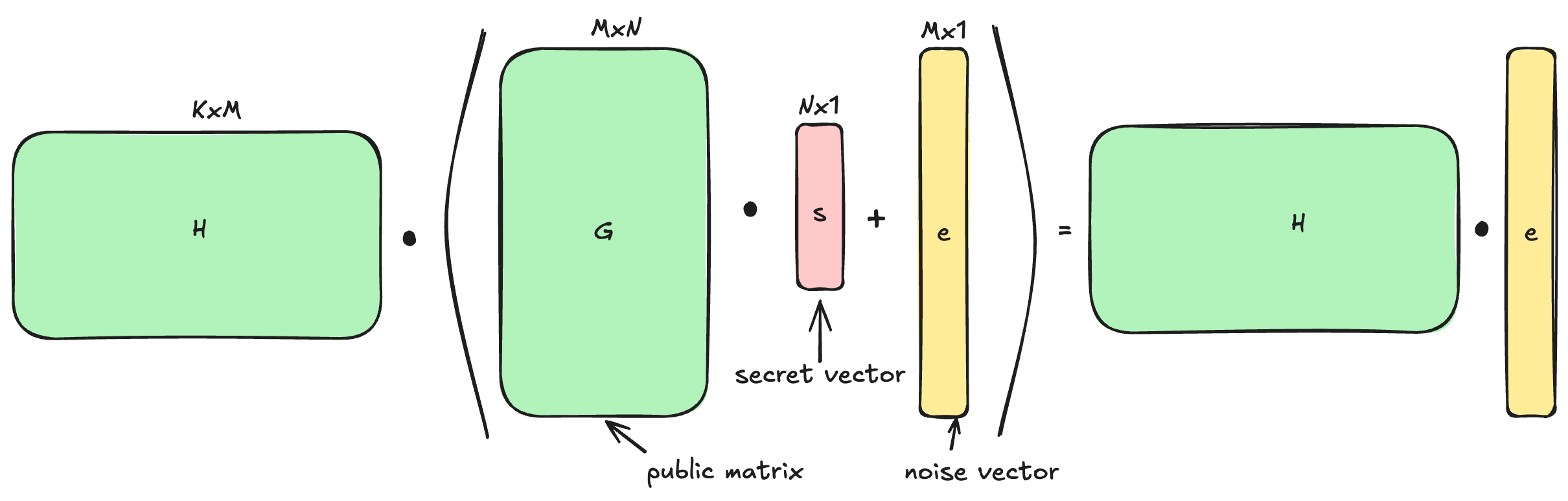
We now have:
- , a secret binary () vector
- , a public binary matrix
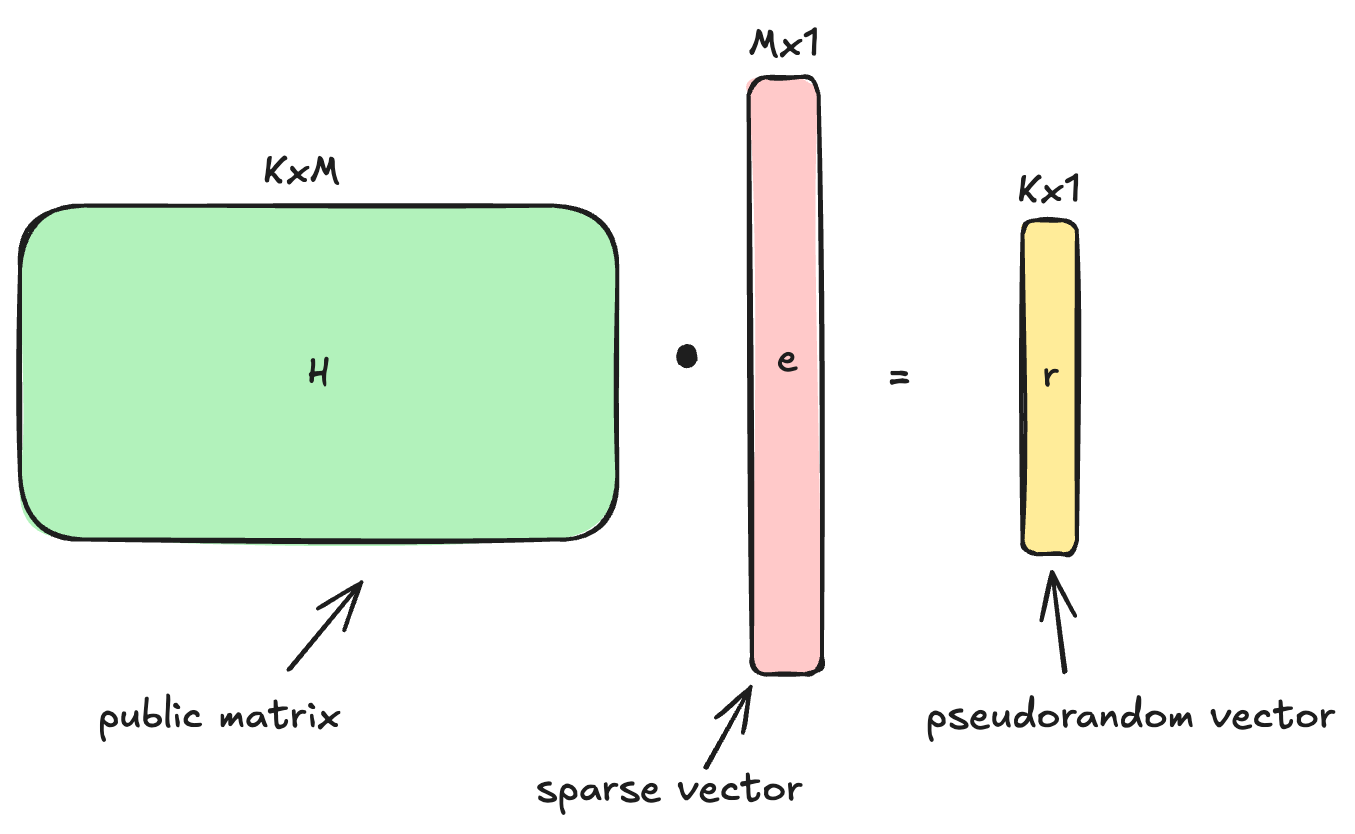
This new problem:
given and , find a sparse vector such that
is known as the syndrome decoding problem.
We transformed the problem from "find s given noisy linear combinations of s" to "find the noise pattern e given its syndrome ”.
SPVOLE: all-but-one construction#
To build a full silent VOLE, we start with a simpler primitive: Single-Point VOLE (SPVOLE).
SPVOLE is just like standard VOLE, but with one key constraint:
The sender’s vector is sparse, it’s a binary vector of Hamming weight 1. That is: is zero everywhere except at a single index , where it equals 1:
At first glance, this seems useless… but in fact, SPVOLE is the core component in expanding a small number of base VOLEs into a large batch of pseudorandom ones using LPN.
Generating VOLEs with GGM
Recall that a GGM tree can expand a single seed into pseudorandom values. Here's the idea:
- the verifier generates a GGM tree and gets all leaves
- the prover wants to learn all but one of these leaves, the one corresponding to a secret index
How can the prover get values without revealing ?
By using Oblivious Transfers, one per GGM tree level.
Below is a GGM tree with 8 leaves (depth 3). The prover selects a secret index , which corresponds to the leaf C010. Through carefully chosen OTs, the prover receives all seeds except for the path to C010.
graph TD
S[root seed]
S --> A0[Node A0]
S --> A1[Node A1]
A0 --> B00[Node B00]
A0 --> B01[Node B01]
A1 --> B10[Node B10]
A1 --> B11[Node B11]
B00 --> C000[Node C000]
B00 --> C001[Node C001]
B01 --> C010[Node C010]
B01 --> C011[Node C011]
B10 --> C100[Node C100]
B10 --> C101[Node C101]
B11 --> C110[Node C110]
B11 --> C111[Node C111]
style C010 fill:#a8324c,color:#000
style A1 fill:#9f6,color:#000
style B00 fill:#9f6,color:#000
style C011 fill:#9f6,color:#000
The prover obtains the following seeds from the OTs:
- A1 : allows reconstruction of
C100,C101,C110,C111 - B00 : allows reconstruction of
C000,C001 - C011 : directly received
Together, these seeds give the prover access to 7 out of 8 leaves, everything except C010, which corresponds to their chosen index .
We’ll call the values generated by the verifier (the leaves of the GGM tree), and the vector of values received by the prover (the N-1 leaves they can reconstruct).
Getting the VOLE
The verifier computes the sum of all pseudorandom values and subtracts their private scalar :
The value is sent to the prover.
The prover computes the missing value by subtracting the sum of their known ’s from :
Now the prover holds:
- a sparse vector , where , all others zero
- a full vector , including the reconstructed missing element (hidden with
The verifier holds:
- The full pseudorandom vector (the leaves of the GGM tree)
- Their secret
And together, the following VOLE relation holds:
Concrete example
Let’s take , so the GGM tree has depth 3 and produces 8 leaves.
Let’s work in the finite field . Suppose the verifier holds:
(remember: corresponds to the GGM tree leaves)
The prover selects a random index , and thus defines the sparse vector:
From the GGM tree and OTs, the prover reconstructs all leaves except index 5:
The verifier computes:
The prover fills in the missing value:
So now the prover holds:
You can verify that:
holds true.
Punctured PRF You might come across the term “punctured PRF” in the context of this construction.
The GGM tree doesn’t just give us pseudorandom values, it gives us structured access to them. By revealing certain seeds and withholding others, we can simulate access to a punctured pseudorandom function (punctured PRF): a function that behaves like a random PRF everywhere except at one point, which remains unknown.
This is exactly what we need for Silent VOLE functionality: the verifier evaluates a PRF at all points, while the prover gets access to every output except at a secret index . That single “missing value” defines a sparse vector with a 1 at position and 0s elsewhere. Perfect for constructing a single-point VOLE. Best of all, this can be done with only OTs instead of , thanks to the binary structure of the GGM tree.
SPVOLE + GGM + LPN: large pseudorandom VOLE#
By combining the GGM tree and the LPN assumption, we can generate a large number of pseudorandom VOLE correlations efficiently and with minimal communication.
Recall two key ideas:
- In SPVOLE, the prover holds a sparse vector (with a single 1), and the verifier holds a vector such that:
- VOLE commitments are additively homomorphic, meaning we can combine multiple SPVOLE instances to forme a larger, more complex correlation
Now, supposed we generate independant SPVOLEs. We can aggregate them:
- Verifier computes:
- Prover computes:
The resulting vectors still satisfy the VOLE equation:
Here, is not longer of Hamming weight 1, but of weight : this is exactly the form expected in the LPN setting.
Apply LPN assumption
Now, we use a public binary matrix to compress this correlation. Multiplying both sides of the VOLE equation by , we get:
This is now a pseudorandom VOLE:
- the verifier holds and
- the prover holds and
The key insight is that is indistinguishable from random, due to the hardness of the LPN problem.
And yet the VOLE structure is preserved under this transformation.
Thanks to GGM trees, we can expand a small seed into a massive sparse vector efficiently.
Thanks to LPN, we can compress the VOLE structure and still maintain pseudorandomness and security.
And best of all, communication remains minimal, even though we've expanded to millions of VOLE instances.
Later, we’ll see how to “correct” (or “derandomize”) these pseudorandom VOLEs to make them commit to a specific witness, turning them from random into meaningful.
Subfield VOLE#
You’ll often come across the term "subfield VOLE", which can be a bit confusing at first, but it’s actually quite simple.
In a standard VOLE, the shares are defined over a single field
- Prover has:
- (secret values)
- (the MACs)
- Verifier holds:
- (global secret)
- (the evaluations)
Now, in subfield VOLE, the idea is to work in different fields.
Many times we’ll want to work in binary fields (for committed values ), but for security we can’t have in such a small field. So we work in an extension field.
- the prover’s secret vector lives in a small field, typically
- the rest, , and , live in a larger extension field for cryptographic security
So we have:
Obviously, the core VOLE equation still holds.
But because the multiplication now mixes elements from two different fields, it’s referred to as a subfield VOLE: the committed values come from a subfield of the field used for the MACs and verifier shares.
This setup is common in applications like zero-knowledge proofs and MPC, where binary witnesses are more natural or efficient to work with, but the security requires a larger field.
Sources#
https://crypto.stanford.edu/pbc/notes/crypto/ggm.html
https://blog.chain.link/realizing-spvole/
https://geoffroycouteau.github.io/assets/pdf/hdr.pdf
https://medium.com/zkpass/learning-parity-with-noise-lpn-55450fd4969c